
GitLab CI : Intégré comme jamais

Dernièrement, je constate que la CI (Continuous Integration) est un skill relativement rare chez les développeurs, même pour des profils expérimentés. Sans en être un expert absolu, je voulais en livrer ma vision et quelques éléments pour démarrer. Je présente dans cet article une intégration continue "type" que j'ai utilisée dans l'un de mes projets, avec GitLab CI et mon propre serveur runner.
Rappel sur la CI
L'objectif
La plupart du temps, les développeurs écrivent du code. L'intégration continue encourage la fusion (merge) fréquente de ce code dans le projet, plutôt que d'attendre l'approche d'une livraison pour y intégrer tous les derniers développements simultanément. Cela permet de drastiquement diminuer la quantité de conflits à résoudre entre feature branches. Les équipes de QA apprécient aussi la réduction de la durée/intensité de leurs sessions de test.
En pratique
Pour augmenter la fréquence des fusions, il est impératif que chaque développeur sache le plus rapidement possible si ses modifications entraînent des régressions. La CI a pour but d'automatiser les tâches garantissant la santé du code : lint, compilation, mesure de qualité, exécution des tests, etc. Ces tâches sont ainsi exécutées à chaque modification du code d'une branche, pour déterminer si le nouveau code est intégrable sans risque. Les erreurs sont ainsi détectées très tôt dans le processus de développement (fail fast!).
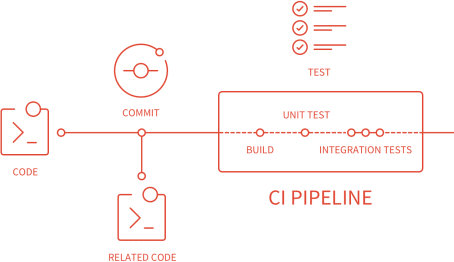
En plus des outils de mesure de la qualité et des tests automatisés déjà présents dans le projet, il faut investir dans l'écriture d'un pipeline d'intégration continue. Cet investissement est vite rentabilisé par un gain significatif de productivité (confort, confiance).
Une bonne pratique consiste à configurer l'interdiction de Merge une branche dont le pipeline d'intégration a échoué, puisque le code est jugé non-conforme. La branche principale gagne naturellement en "capital confiance", quand on sait que le code qu'elle contient est forcément validé (en plus d'avoir été revu par des collègues).
Ce que j'utilise : GitLab CI
GitLab CI est la solution open source de CI/CD intégrée à la plateforme GitLab, elle-même open source. Chaque push sur chaque branche du projet va déclencher l'exécution du pipeline d'intégration. Elle est bien documentée et gratuite dans la limite de 400 minutes par mois sur les shared runners : au-delà, il faut payer, ou utiliser son propre runner.

Pipeline visible sur la page d'une Merge Request
Il existe d'autres solutions, comme les GitHub Actions, Travis ou CircleCI. Contrairement à ses concurrents, GitLab CI n'offre pas encore de runner "clé en main" sous Mac OS (donc pas de build Xcode).
Dans mon équipe, la compilation de nos applications mobiles (iOS inclus) est confiée à Bitrise.
Enfin, il est possible de transformer n'importe quelle machine (PC, Macbook, carte ARM, serveur dédié...) en runner, en y installant GitLab Runner. J'en dis plus dans la suite de l'article !
🔄 Dessine-moi un pipeline
Chaque pipeline est constitué d'un ou plusieurs jobs (travaux) regroupés en stages (étapes). Les jobs d'une même stage sont exécutés en parallèle. Si un job échoue, la stage échoue et interrompt l'exécution du pipeline : les stages suivantes ne sont pas exécutées. À moins que le job n'ait été autorisé à échouer. La terminologie change d'une plateforme à une autre, mais on retrouve souvent la même construction. CircleCI parle de Workflows et de Jobs, Travis CI de Build Stages et de Jobs.
La documentation des Pipelines GitLab CI est très bien faite et il existe aussi de nombreuses templates officielles prêtes à l'usage.
👮 Gardons à l'esprit, pour la suite de l'article, qu'un pipeline se doit d'être déterministe et aussi rapide que possible.
La définition du pipeline se fait dans un fichier .gitlab-ci.yml à la racine du projet. GitLab détecte automatiquement ce fichier. Dans mon projet (mono-repo, fullstack), j'ai défini les stages suivant :
# .gitlab-ci.yml
stages:
- build-and-test
- deployment
Et je vais présenter, ici, deux jobs de la stage build-and-test : la construction de l'image docker de l'application frontend et celle de l'application backend. Ces jobs sont exécutés, à la racine du dépôt, à chaque fois qu'une modification du code est poussée dans ce dernier.
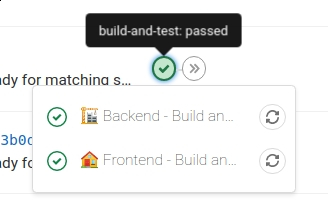
Quand toutes les stages sont exécutées avec succès, le commit est "passé".
Frontend
# .gitlab-ci.yml
# [...]
🏠 Frontend - Build and tests:
stage: build-and-test
image: docker:stable
script:
- docker build -f app/Dockerfile -t frontend-build .
Le job nommé 🏠 Frontend - Build and tests, associé à la stage "build-and-test", utilise l' image docker docker:stable pour exécuter son script qui consiste en un docker build. Le Dockerfile app/Dockerfile va :
- Installer les modules NPM (
yarn install) - Valider la bonne compilation de l'ensemble de la codebase TypeScript (
yarn tsc) - S'assurer du bon linting du code (
yarn lint) - Vérifier que le projet puisse être construit (
yarn build) - Exécuter les tests unitaires et end-to-end (Cypress) (
yarn testetyarn e2e)
# ./app/Dockerfile
# Image cypress : node, npm, yarn + cypress et ses dépendances
FROM cypress/base:14.15.0
WORKDIR /app
ENV NODE_ENV='development'
ENV TZ='UTC'
ENV CI=true
# dans ce projet fullstack, le répertoire ./app contient le frontend
ARG FRONTEND_DIR='/app'
# le frontend et le backend sont des yarn workspaces: chacun son package.json
COPY ${FRONTEND_DIR}/package.json /app/package.json
COPY yarn.lock /app/yarn.lock
RUN yarn install --frozen-lockfile --prefer-offline --no-progress --no-emoji
ADD ${FRONTEND_DIR}/. /app
RUN yarn tsc:all
RUN yarn lint
RUN yarn build
RUN yarn test
RUN yarn cypress install
RUN yarn e2e:ci # start-server-and-test start http://localhost:8000 cypress run
CMD yarn start
Si l'une de ces tâches échoue, la commande docker build échoue, entraînant l'échec du job.
Il est évidemment possible d'exécuter ces commandes yarn directement dans le script du job :
# .gitlab-ci.yml
# [...]
🏠 Frontend - Build and tests:
stage: build-and-test
image: node:14.15.0-stretch-slim # on utilise une image node directement !
script:
- yarn install --frozen-lockfile --prefer-offline --no-progress --no-emoji
- yarn tsc:all
- yarn lint
# ...
L'avantage d'exécuter ces tâches en construisant une image Docker est de profiter de son build cache incrémental 🐋, quand le pipeline est exécuté systématiquement sur la même machine. Ainsi, à la prochaine exécution de docker build, yarn install ne sera pas ré-exécuté si package.json n'a pas été modifié. Même principe pour lint, build, test : pas exécutés si le code à copier dans ./app n'a pas été modifié.
Pour davantage d'explications, consultez cet article 🐳.
Et, Oui, j'aurais pu utiliser un build multi-stages mais ce n'est pas le sujet de l'article !

Backend
# .gitlab-ci.yml
# [...]
🏗 Backend - Build and tests:
stage: build-and-test
image: docker/compose:latest
script:
- docker build -f backend/Dockerfile -t backend-build .
- docker-compose -f backend/ci/docker-compose.yml up --force-recreate --exit-code-from backend
Le job construit une image Docker à partir du Dockerfile backend/Dockerfile, à la manière du projet frontend (install, lint, build, test...).
Si l'image est construite, alors docker-compose est utilisé pour lancer deux containers : un pour lancer les tests d'intégration et end-to-end de l'application backend, un autre pour l'émulateur de la base de données (Firestore).
# backend/ci/docker-compose.yml
version: '3.2'
services:
backend:
image: backend-build
environment:
FIRESTORE_EMULATOR_HOST: 'firestore-emulator:8081'
FIREBASE_PROJECT_ID: 'firestore-testing'
CI: 'true'
depends_on:
- firestore-emulator
command:
- bash
- -c
- |
for ((i=0;i<30;++i));
do curl -s firestore-emulator:8081 && break || (echo "Waiting for firestore emulator..." && sleep 1);
done;
yarn integration && yarn e2e;
firestore-emulator:
# using "alpine" as it is ~600MB smaller (but JDK 8+ is still required)
image: google/cloud-sdk:316.0.0-alpine
expose:
- 8081
command:
- bash
- -c
- |
apk --update add openjdk8-jre
gcloud --quiet beta emulators firestore start --project=firestore-testing --host-port 0.0.0.0:8081
En passant --exit-code-from backend à docker-compose, le job réussit seulement si la commande du service backend (yarn integration && yarn e2e) réussit.
Kudos à mon ex CTO @DigitalLumberjack pour cette technique 💗.
Plutôt que d'utiliser Docker Compose afin de lancer un deuxième container pour la base de données, il est aussi possible d'utiliser les Services de GitLab CI. Cela demande moins de travail, mais ce n'est pas exécutable sur votre machine, contrairement à Docker Compose.
Dans le cas de Firestore, il n'existe aucun service dédié, donc pas le choix : on télécharge l'image de Google Cloud et on lance l'émulateur à la main.

Et c'est tout ?
C'est un bon début ! Bien sûr, on peut aller beaucoup plus loin, en intégration comme en déploiement. Pour en apprendre davantage sur les possibilités de GitLab CI, je recommande (entre autres) :
- Les jobs conditionnels, avec
rules, qui remplaceonly/expect: pratique, par exemple, pour déployer automatiquement l'application sur un environnement Staging quand le pipeline est exécuté sur la branchemaster. when, utilisable avec ou sansrules, permet avec la valeurmanuald'ajouter des jobs à lancer manuellement (e.g. "Déployer en production"), mais aussi des jobs automatiquement lancés suite à un échec du pipeline (on_failure), etc.
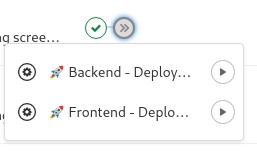
Job manuel : déployer en production ("master" seulement).
🚀 Frontend - Deploy production:
stage: production
image: node:14.15.0-stretch-slim
script:
- yarn install --frozen-lockfile
- echo "${FIREBASE_PKEY_FILE_JSON}" | base64 -d > ./firebase-credentials.json
- yarn firebase deploy --token "${FIREBASE_TOKEN}"
rules:
- if: '$CI_COMMIT_BRANCH == "master"' # seulement possible avec "master"
when: manual
- Les
artifacts, fichiers conservés après l'exécution d'un job et téléchargeable par l'interface de GitLab. Utiles pour extraire les logs d'un test de performances, des captures d'écran et vidéos de tests Cypress, des rapports/extraits, etc.
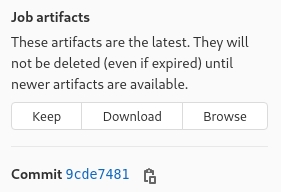
Téléchargeables sous forme d'archive, ou à parcourir dans l'explorateur de GitLab Web
parallelpermettant plusieurs exécutions simultanées d'un même job.

Les tests E2E d'un autre projet, répartis dans 4 instances d'un même job.
-
L'injection de variables d'environnement dans GitLab CI, rendues accessibles dans
.gitlab-ci.yml. -
La directive
cachequi permet de transférer des fichiers d'un job à un autre. Utile si vous ne pouvez/voulez pas profiter du cache de build incrémental en lançant vos jobs dans desdocker build. -
En quête de performances pour les machines virtuelles servant de runners, GitLab CI permet de configurer un cache distribué (AWS S3, Cloud Storage, Azure...).
🏃 Dessine-moi un runner
Utiliser une machine dédiée peut mener à la réduction du temps d'exécution des pipelines : meilleur hardware 🚀, réutilisation du cache Docker 🐳 (docker build plus rapide) et du cache npm/yarn 📦 (les packages déjà en cache ne sont pas téléchargés à nouveau).
Accessoirement, en n'utilisant pas les shared runners de GitLab, on peut aussi :
- Éviter l'envoi de fichiers/codes sensibles sur des machines qu'on ne possède pas
- Utiliser la CLI Xcode si disponible sur la machine hôte (macOS)
- S'affranchir des limitations (commerciales) sur les shared runners
Si vous souhaitez déployer votre propre flotte de runners (kubernetes, cloud autoscaling, etc), il existe des exemples officiels. Pour ce projet personnel, j'ai utilisé un seul serveur dédié.
Il suffit d'installer l'utilitaire GitLab Runner sur la machine en question (avec docker pour executor) et d'enregistrer le runner dans votre instance GitLab. Les stages du pipeline seront directement exécutés sur la machine enregistrée.
💰 Pour de meilleures performances si votre budget est serré, dans le cas d'un serveur dédié, favorisez (en priorité) un SSD plutôt qu'un disque dur mécanique. Le reste (CPU, RAM) dépendra de ce que vous ferez/lancerez dans vos pipelines. Il vous appartient d'étudier toutes les possibilités en terme de budget (votre machine de travail, un serveur dédié, une flotte de machines virtuelles spot/préemptives...).
Une note sur Cypress
Si vous rencontrez des problèmes de mémoire (Out of memory) lorsque vous exécutez vos tests e2e utilisant Cypress, c'est peut-être dû à une shared memory (shm) insuffisante, Docker lui allouant 64MB par défaut. Si vous utilisez votre propre runner, vous pouvez augmenter celle-ci en conséquence, en passant par exemple --shm-size=1G à Docker (dans mon cas, directement à docker build) et en ajoutant la même configuration à /etc/gitlab-runner/config.toml avec le paramètre shm_size :
# [...]
[[runners]]
# [...]
[runners.docker]
# [...]
shm_size = 1073741824
Et avec un projet déjà existant ?
Démarrez petit ! On peut utiliser une image node officielle et directement exécuter yarn build, yarn test, etc, dans le script d'un unique job :
# .gitlab-ci.yml
stages:
- build-and-test
build backend:
stage: build-and-test
image: node:14.15.0-stretch-slim
script:
- yarn install --frozen-lockfile --prefer-offline --no-progress --no-emoji
- yarn lint
- yarn build
- yarn test
Ces quelques lignes suffisent à lancer un pipeline déjà très utile. Dans mon projet "starter" TypeScript, Gatsby, Material-UI (gatsby-gojob-starter), j'ai fourni deux bases de pipeline, une pour CircleCI, une autre pour GitLab CI. Loin d'être des modèles de perfection, elles permettent cependant de se lancer 😬>.
CD, "c'est plus qu'un Job"

Concernant le Continuous Delivery et le Continuous Deployment, un nouvel article serait de rigueur. Dans le cadre de mon projet personnel, j'ai un environnement de production en continuous delivery : la nouvelle version de master est déployée par une action manuelle. Le job ressemble à celui-ci :
🚀 Frontend - Deploy production:
stage: deploy
image: node:14.15.0-stretch-slim
script:
- yarn install --frozen-lockfile
- echo "${FIREBASE_PKEY_FILE_JSON}" | base64 -d > ./firebase-credentials.json
- yarn firebase deploy --token "${FIREBASE_TOKEN}"
rules:
- if: '$CI_COMMIT_BRANCH == "master"'
when: manual
Pour l'environnement de staging, j'utilise une version légèrement modifié de ce job : il est déclenché automatiquement quand une branche est fusionnée à master et vise staging comme hosting target pour déployer l'application vers un domaine Firebase spécifique. On parle ici de continuous deployment.
🚀 Frontend - Deploy staging:
stage: deploy
image: node:14.15.0-stretch-slim
script:
- yarn install --frozen-lockfile
- echo "${FIREBASE_PKEY_FILE_JSON}" | base64 -d > ./firebase-credentials.json
- yarn firebase deploy --token "${FIREBASE_TOKEN}" --only hosting:staging
rules:
- if: '$CI_COMMIT_BRANCH == "master"'
Il est possible de "refactorer" du YAML pour éviter les copy-paste massifs... À vous de jouer 😬.
La technique employée ici est spécifique à Firebase (firebase deploy). Il faut adapter le job aux contraintes techniques (Heroku ? Helm/Kubernetes ? Gestion des environnements...) et professionnelles (Sécurité ? Droits d'accès ? Politique de mise à jour...) de chaque entreprise.
Happy CI/CDing!